-
无法成功安装pandas包
-
使用parser.add_argument设置参数默认值失败
-
成功安装包文件后无法识别
-
python中字符串去除中英文符号的问题
无法成功安装pandas包
情况描述:使用pycharm作为IDE,理论上通过file-settings-project inspect安装需要的包即可。也可以直接在代码编辑器的提示用点击安装,或者在pycharm的终端窗口使用pip命令行安装,但无论哪一种,总提示安装失败。
尝试解决方案:
-
-
根据pycharm提示,安装visual studio工具,成功安装,但依然不能识别;
最终解决方案:
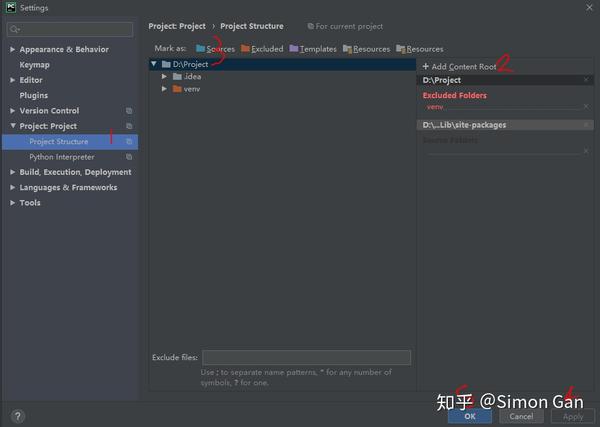
打开Pycharm编辑器。 1)选择File—>settings—>project:pythonWork—>project structure 2)选择右边add content root 3)选择文件夹(project interpreter的位置下site-packages文件夹) 4)Mark as:第一个sources 5)Apply - > OK
作者:Simon Gan 链接:https://zhuanlan.zhihu.com/p/162711312 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
使用parser.add_argument设置参数默认值失败
情况描述:如题。
解决方案:添加nargs='?'表明该参数为可选参数,然后设置默认值。事实上我添加了两个参数,第二个参数没有加这个项,直接设置了默认值也没有问题,不知道为什么。
parser.add_argument(
'source_file',
help='The location of the source ',
nargs='?',
default='Notebook.csv'
)
成功安装包文件后无法识别
情况描述:成功在pycharm中安装包,但是无法识别。
原因分析:这是在使用第一个解决方案后的遗留问题。通过设置,我让pycharm在运行时,从python自己的site-pakages文件夹下去寻找包,而不是在它默认给每个project建立的文件夹下去寻找,这解决了通过pycharm安装包不成功的问题。但当通过pycharm安装包成功的时候,包安装的位置与之前指定的位置不在一处,就导致pycharm运行代码的时候又找不到了。感兴趣的可以pip install 包名,看一眼包的位置。
解决方案:如果之前的包是通过系统终端安装的,那么之后所有的包都通过系统终端命令行安装,就不会发生问题了。
python中字符串去除中英文符号的问题
情况描述:如题。
解决方案:
-
使用正则表达式
import re s = "string. With. Punctuation?" s = re.sub(r'[^\w\s]','',s)
注:以上代码不能移除空格符。
-
使用别人总结好的包
# 去除英文标点符号 import string s = "string. With. Punctuation?" # Sample string out = s.translate(string.maketrans("",""), string.punctuation)
# 去除中文标点符号 def remove_punctuation(line, strip_all=True): if strip_all: rule = re.compile(ur"[^a-zA-Z0-9\u4e00-\u9fa5]") line = rule.sub('',line) else: # 调用zhon包的zhon.hanzi.punctuation函数即可得到这些中文标点。 # 如果想用英文的标点,则可调用string包的string.punctuation函数可得到 punctuation = """!?。"#$%&'()*+-/:;<=>@[\]^_`{|}~⦅⦆「」、、〃》「」『』【】〔〕〖〗〘〙〚〛〜〝〞〟〰〾〿–—‘’‛“”„‟…‧﹏""" re_punctuation = "[{}]+".format(punctuation) line = re.sub(re_punctuation, "", line) return line.strip()
清洗完毕后,有时候我们希望按照多个标点符号来分割
比如只要遇到中文或英文的逗号和句号等符号就分割,可以直接用translate把这些符号翻译为统一的分隔符,再split:
strip_chars = '?"。.,,《》[]〖〗“”'
single_line = single_line.translate(str.maketrans(dict.fromkeys(strip_chars, '#')))
single_line = single_line.split('#')


